Visual Genome or how computers can recognize what happens in an image
 Hello,
Hello,
Automatic representation of images is one of the most challenges of the Computers and Classification sciences. Can computers recognize not just objects but to make sense of what’s actually going on in images?
The ability of to automatically recognize the contents of images is a discipline that is part of a major field called Computer Vision, and deep learning a method by virtue of which machines can learn to analyse and classify images. This branch of Artificial Intelligence (AI) is based on a “set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers with complex structures, or otherwise composed of multiple non-linear transformations”.
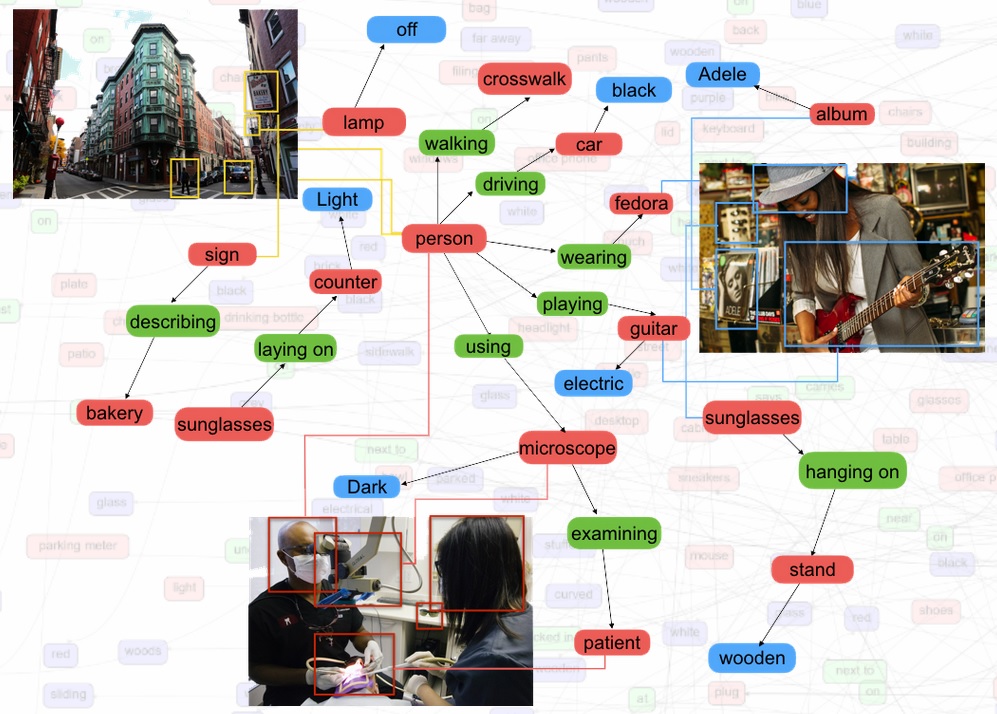
In this research framework is that we have to understand the Visual Genome project. Visual Genome is a dataset of 108,077 images developed by Fei-Fei Li, a professor who specializes in computer vision and who directs the Stanford Artificial Intelligence Lab, together with several colleagues.
The Visual Genome software, as other projects (e.g. Microsoft Common Objects in Context), tries to describe in a human way what happens in an image. In Fei-Fei Li’s words: “You’re sitting in an office, but what’s the layout, who’s the person, what is he doing, what are the objects around, what event is happening?”
The opportunities of this research are enormous, from self-driving cars understanding properly (not just seeing) what’s happen around them to robots that can interact with humans in a better way.
Enjoy it!
Andreu Sulé
University of Barcelona